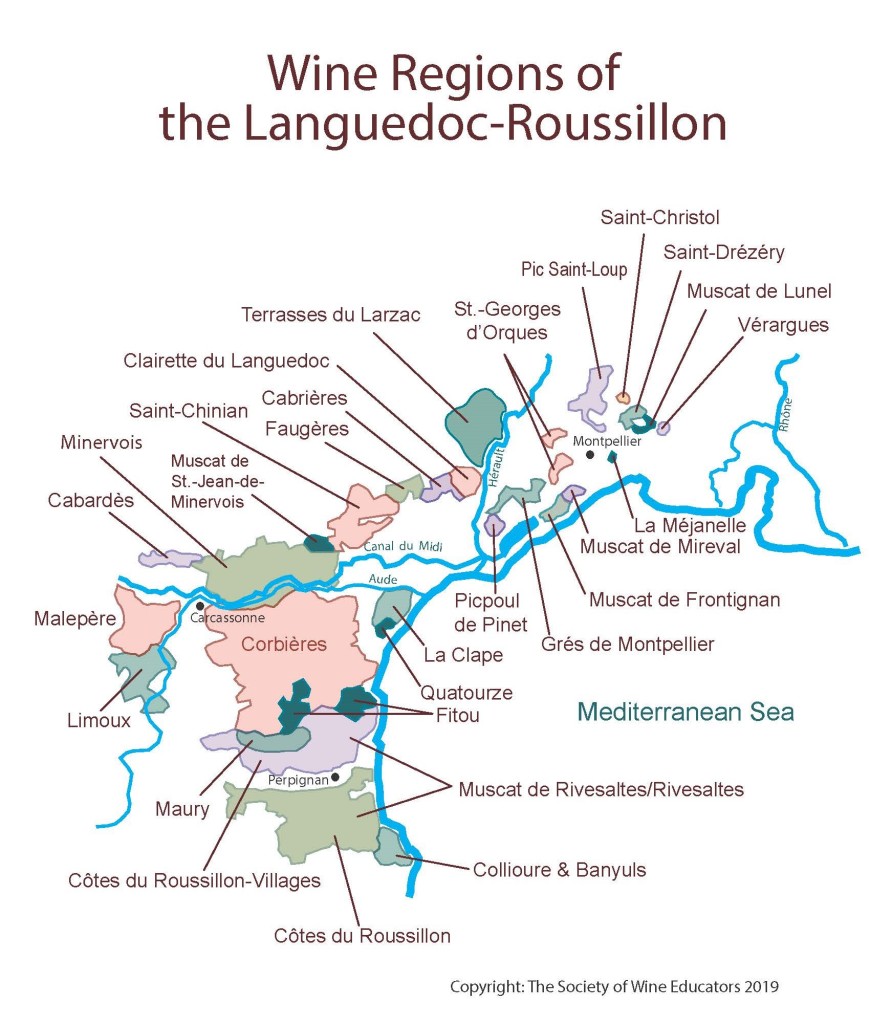
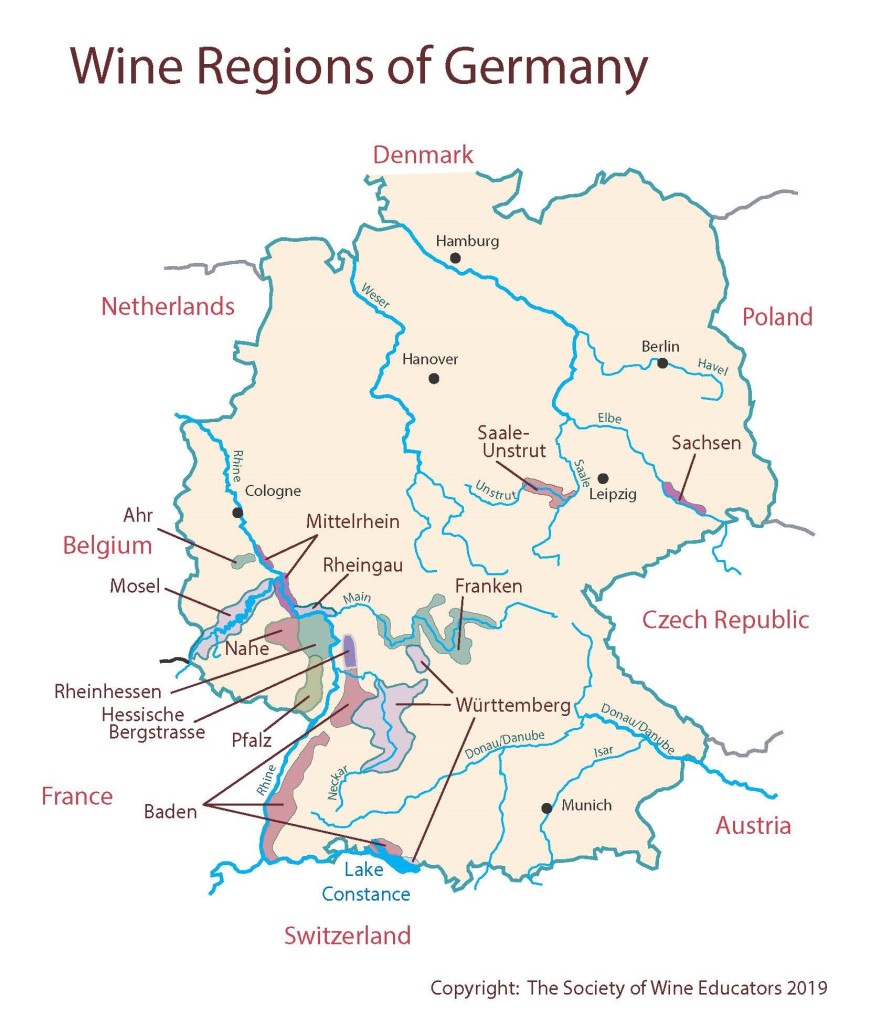
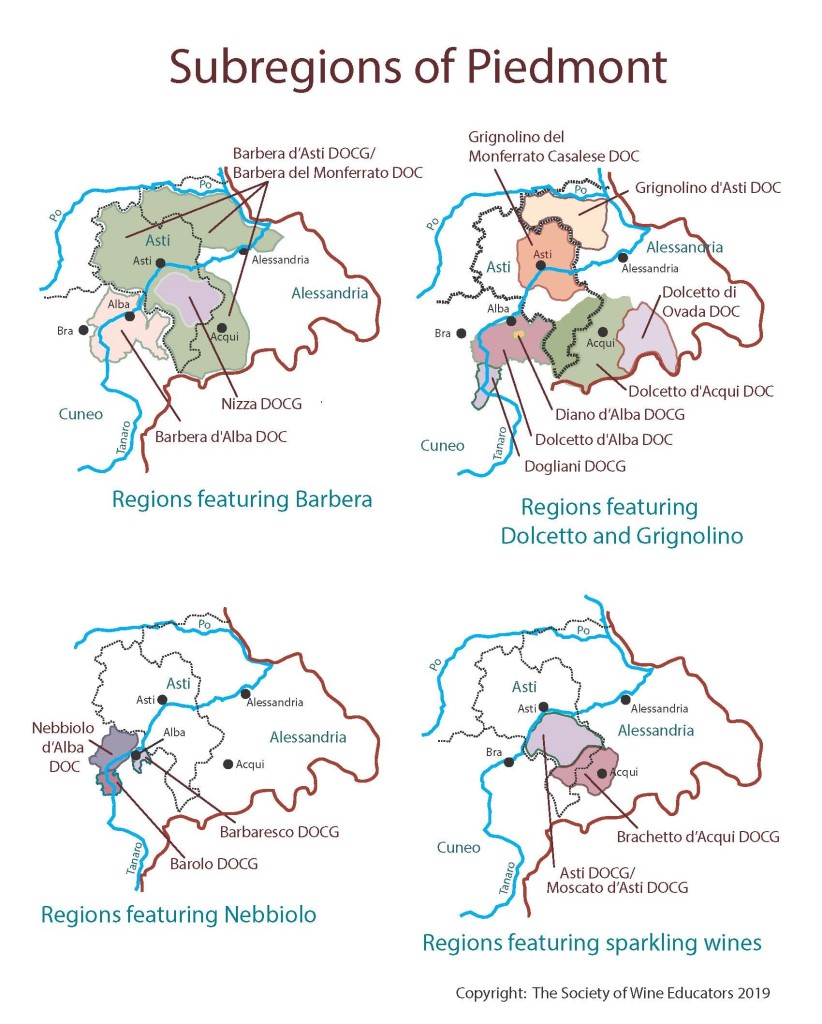
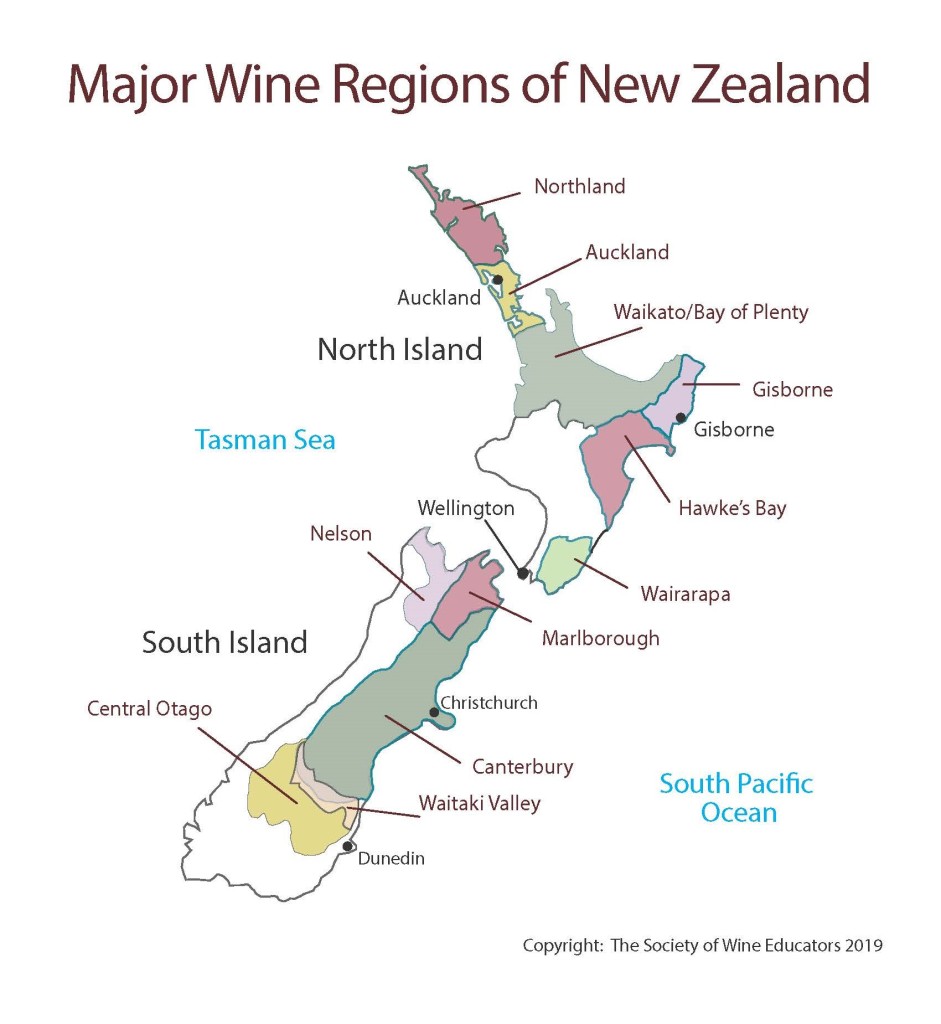
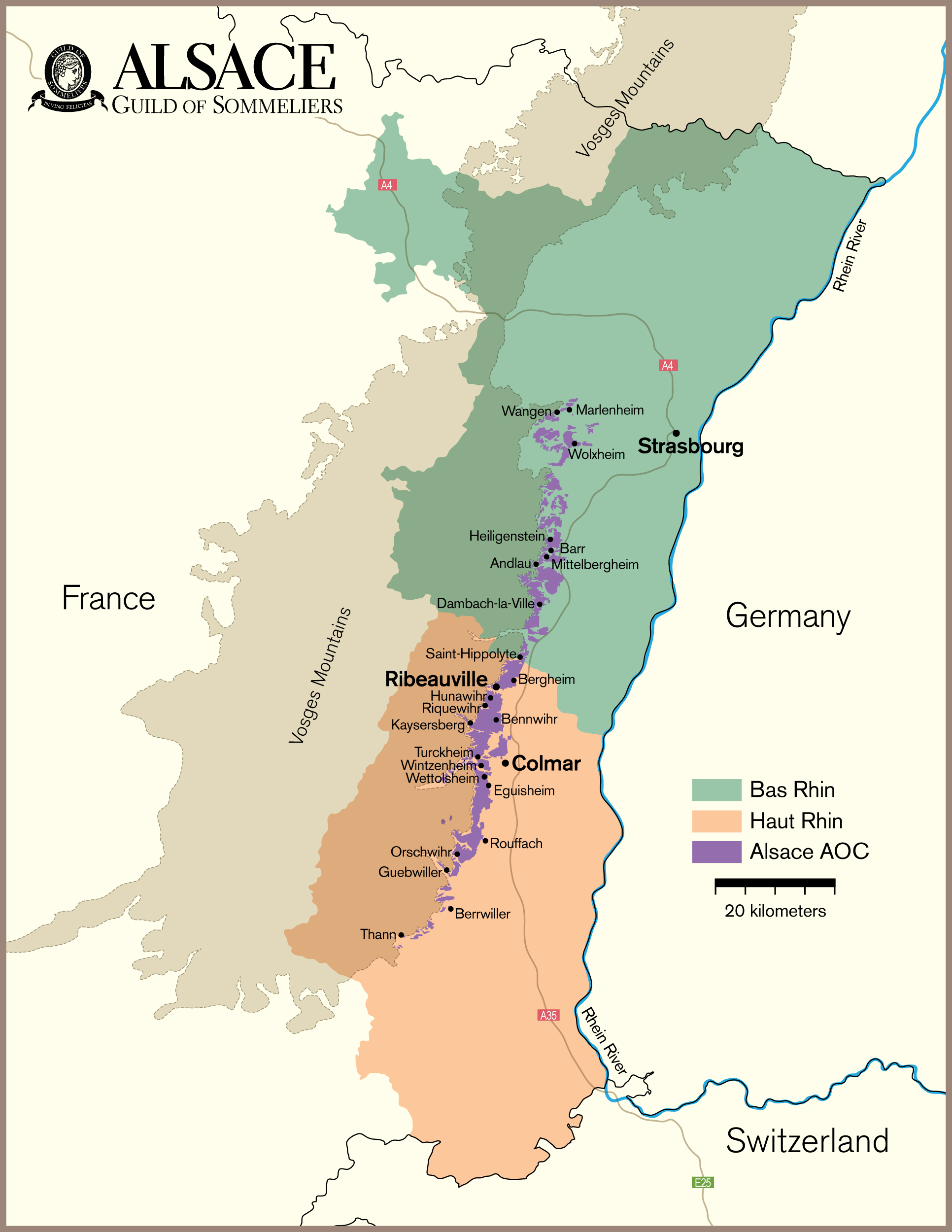
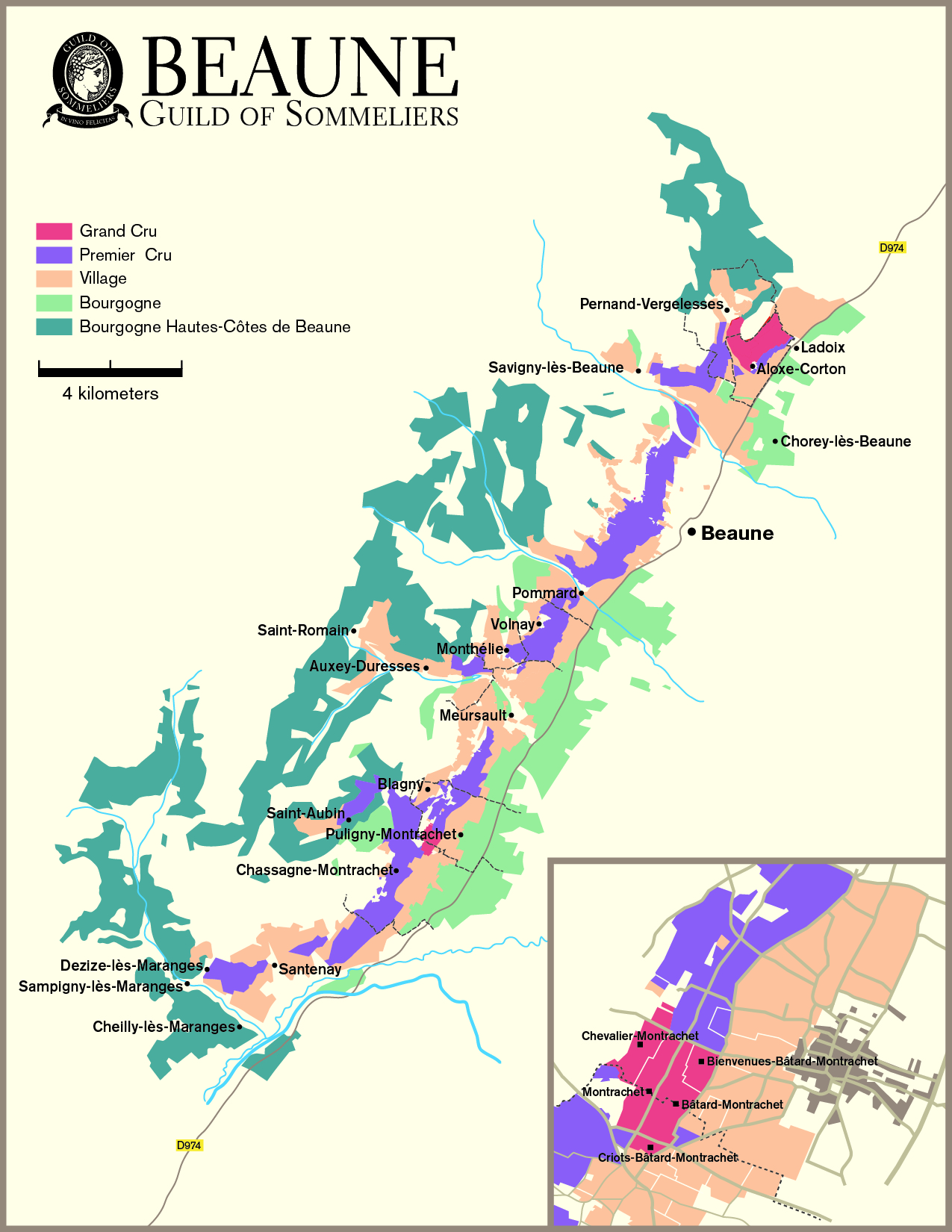
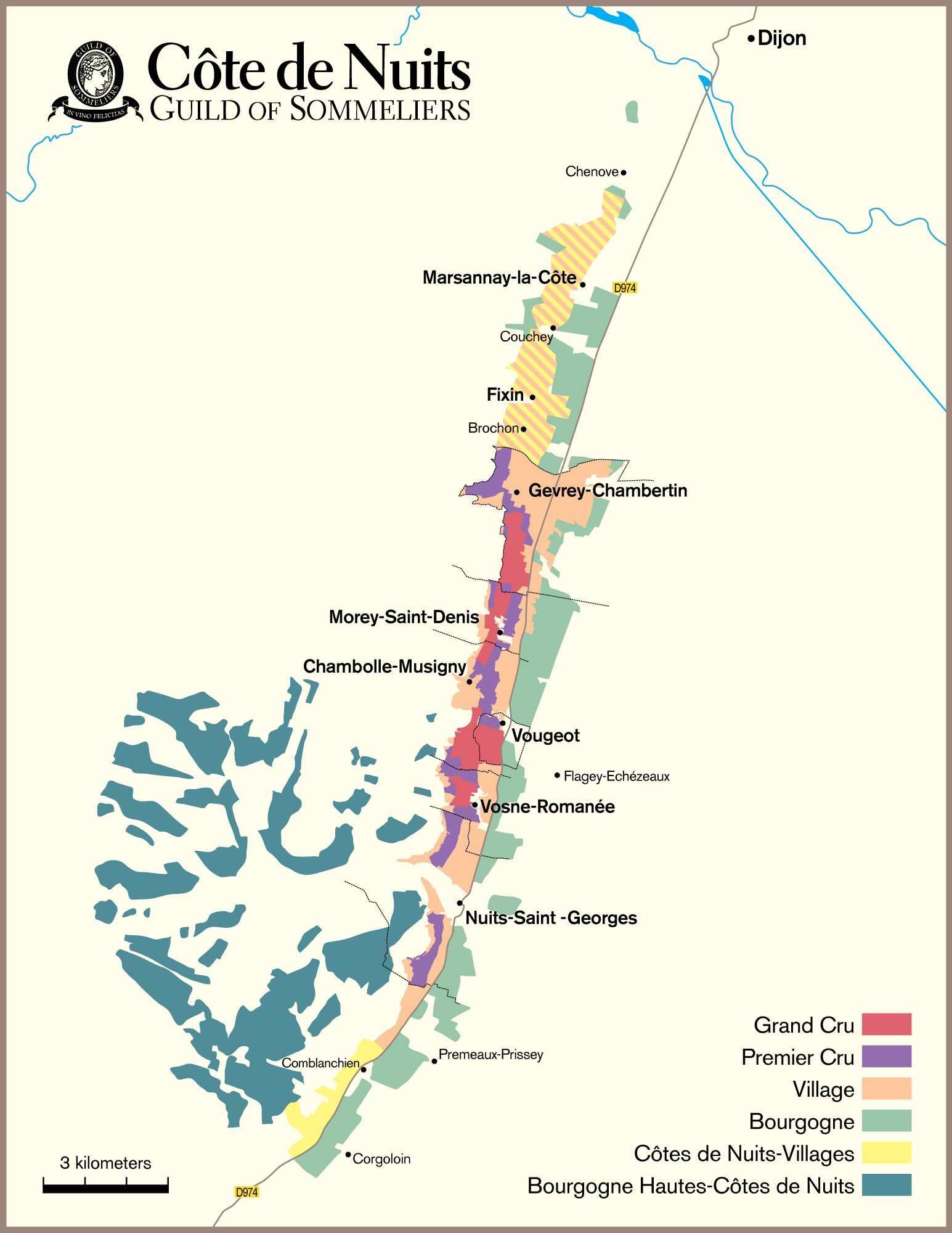
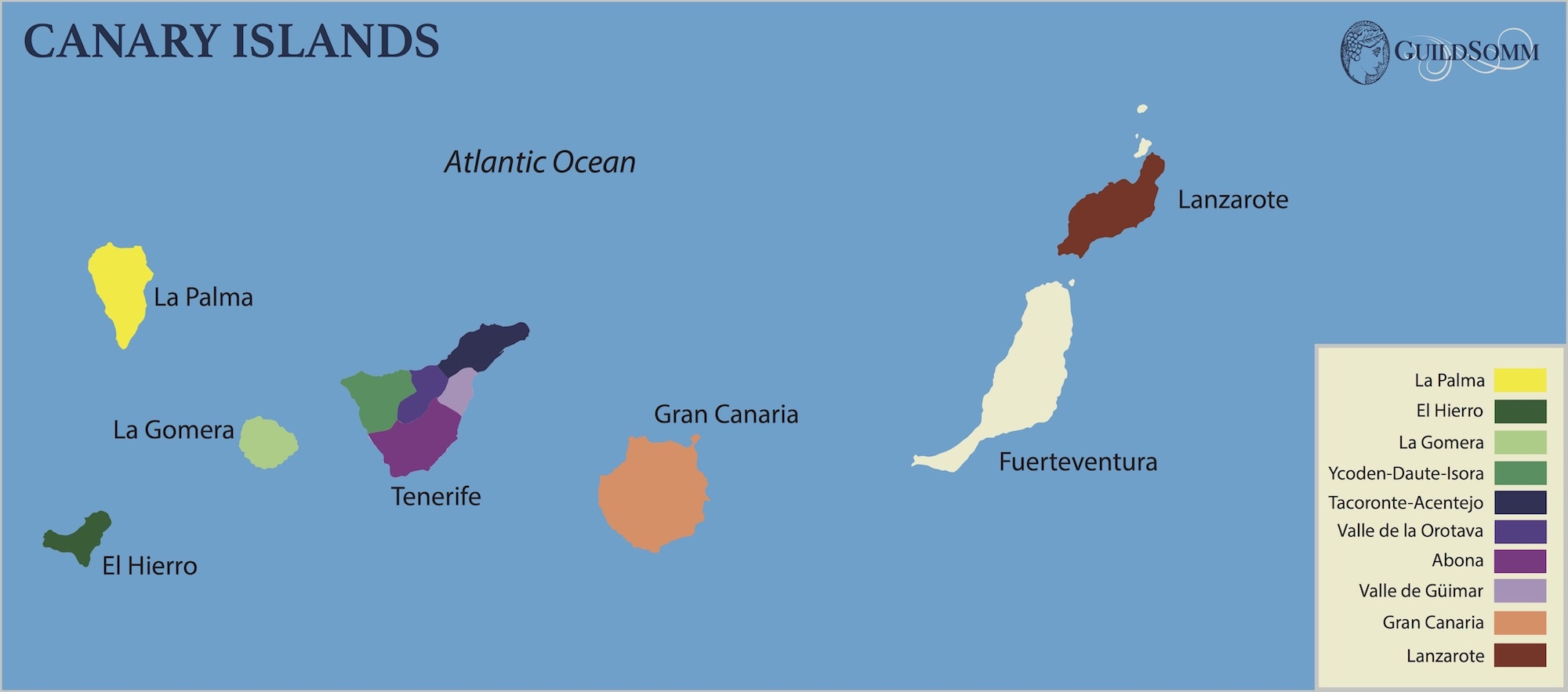
Maps are beloved by the wine world. From my early exposure during the famed course Intro to Wine in college taught by the one and only Cheryl Stanley, to my later studies through the Court, WSET, and (ongoing) MW program, Map drawing as an effective strategy for studying wine theory has been consistently echoed by Cheryl, various Master Sommeliers, Master of Wines, and other senior wine professionals. Some even get into the art and science of cartography -- from Alessandro Masnaghetti, a nuclear-engineer-turned mapman, who made groundbreaking maps of wine regions, especially known for the crus of Barolo and Barbaresco, to Deborah & Steve De Long, a textile designer and an architect, whose maps are a true labor of love.
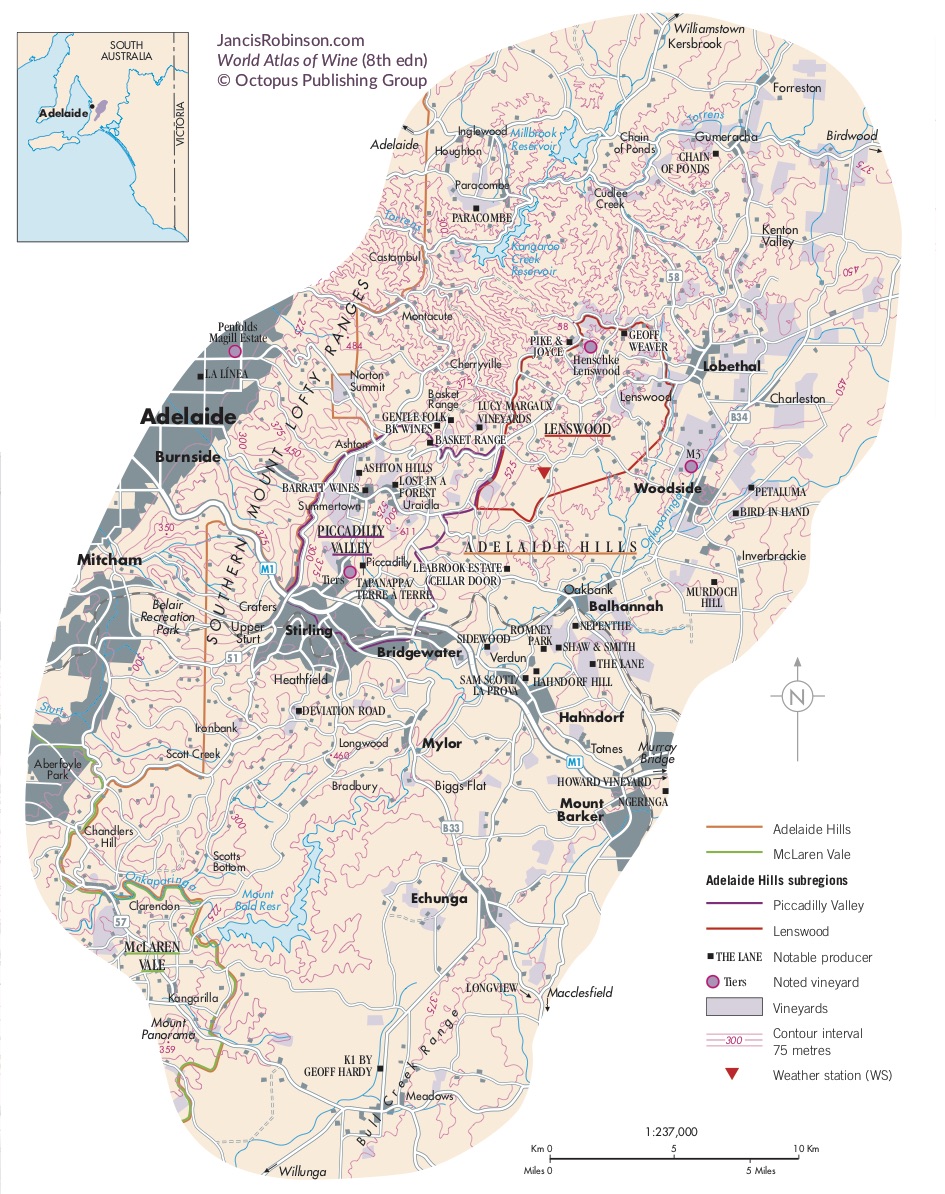
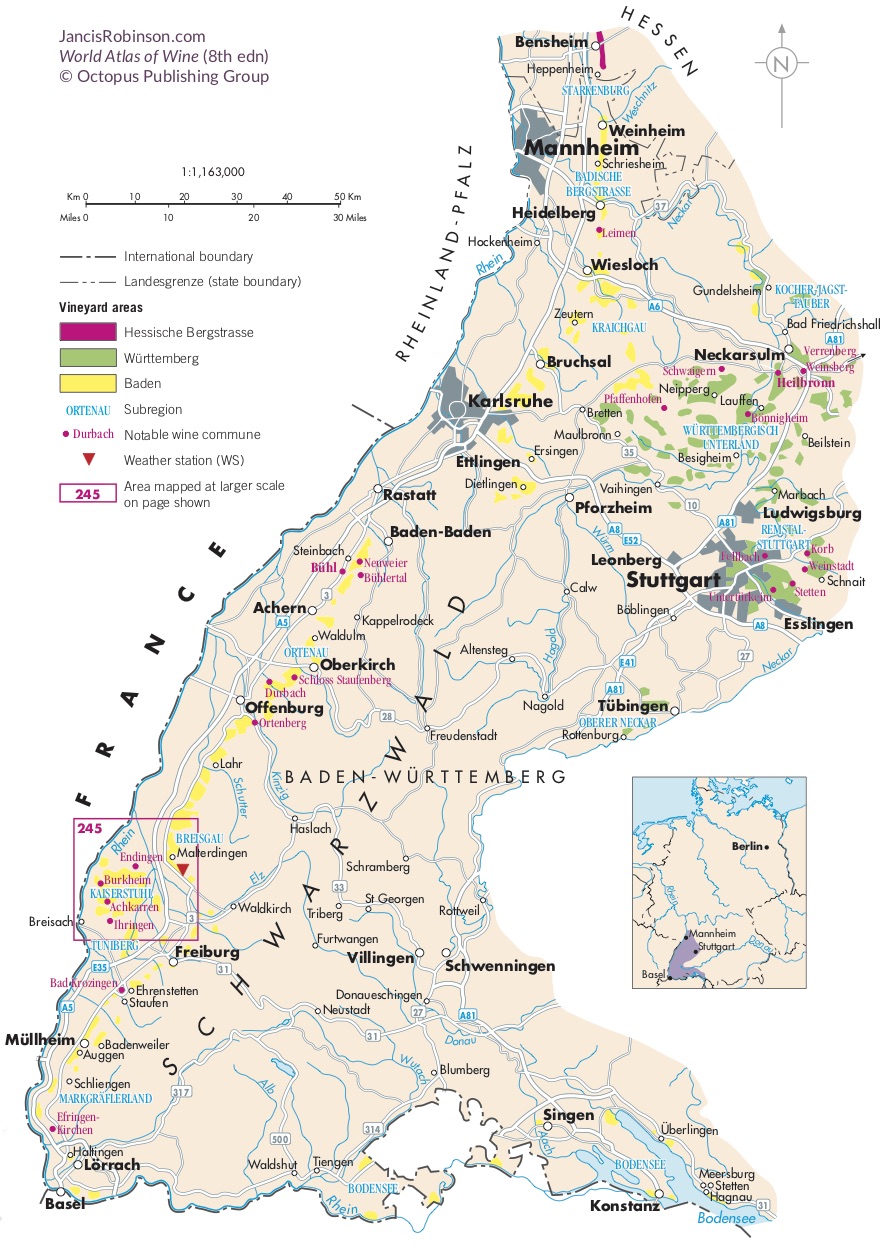
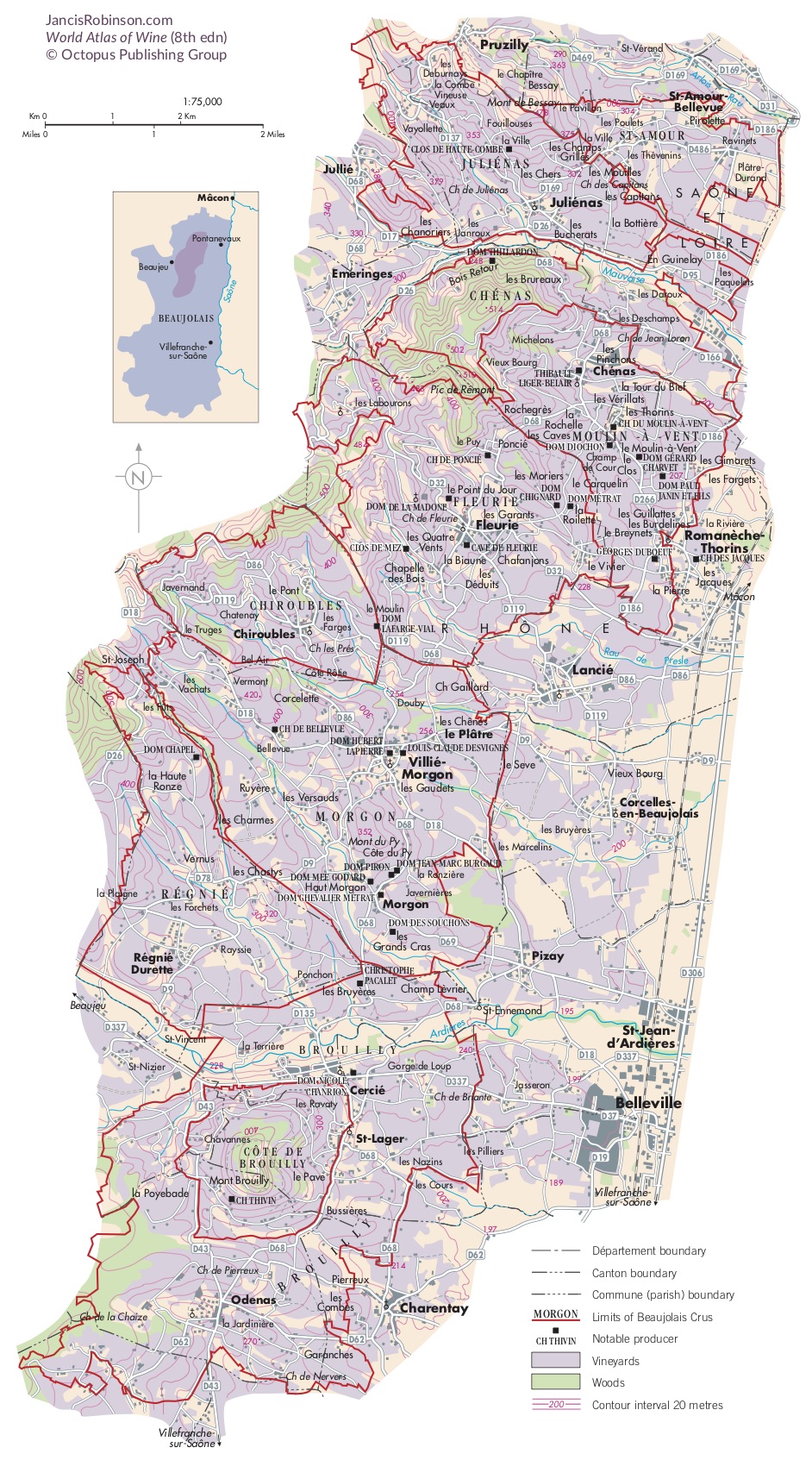
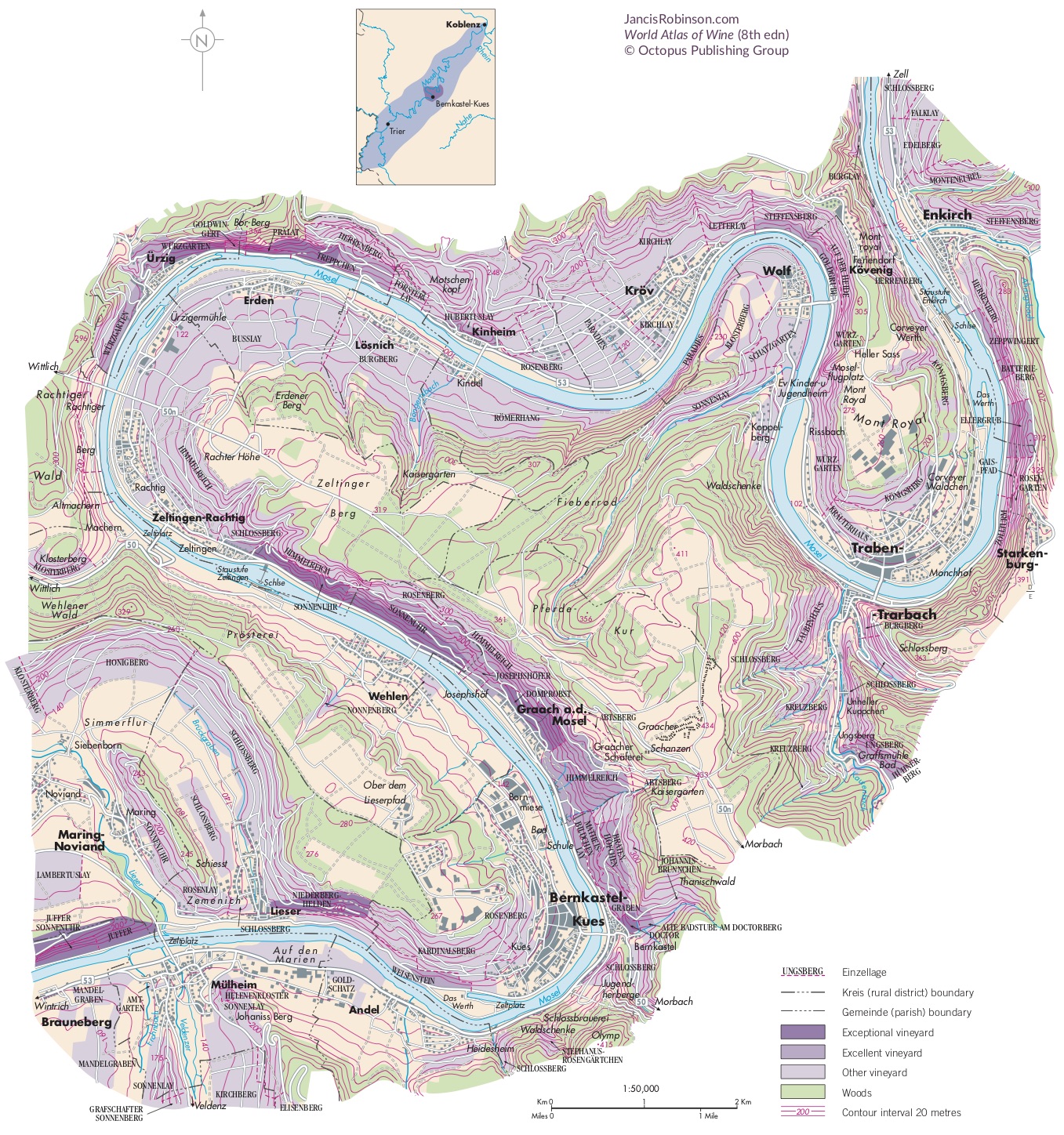
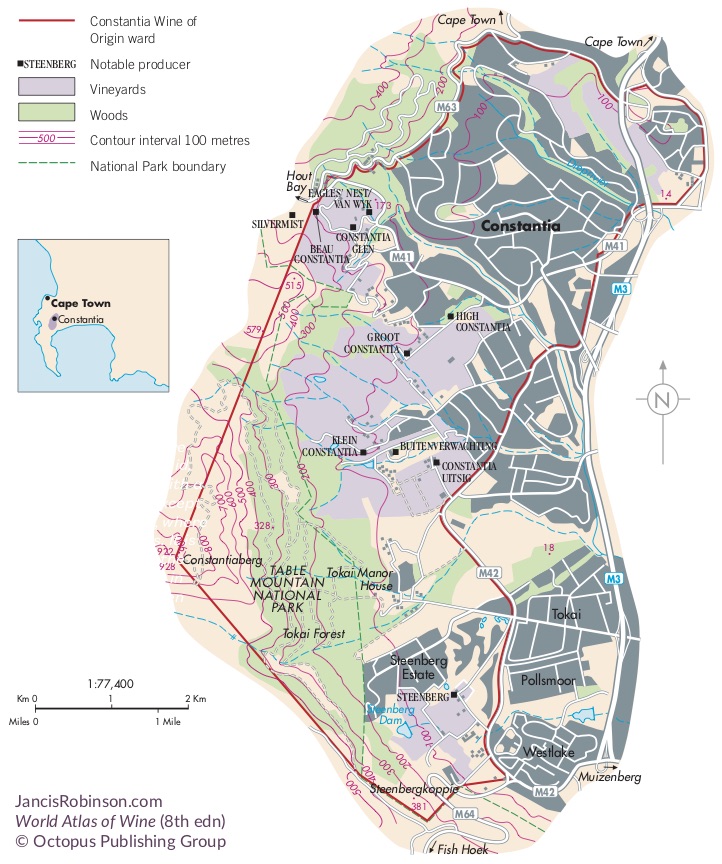
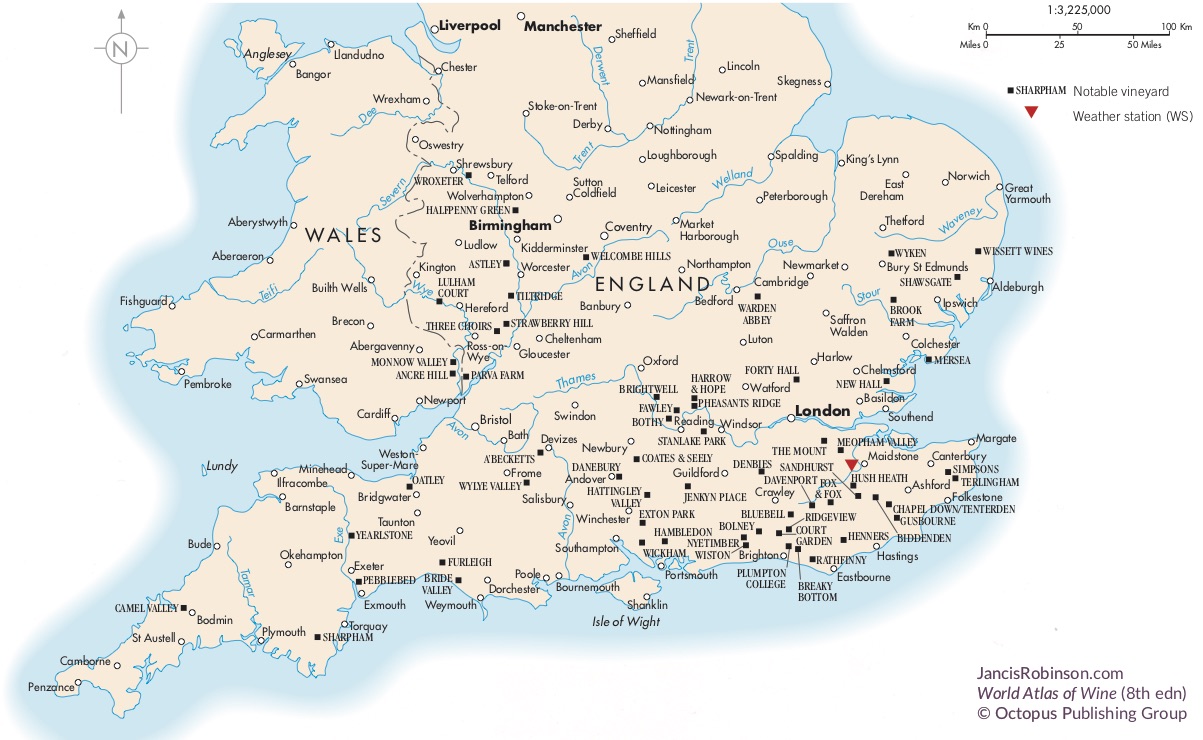
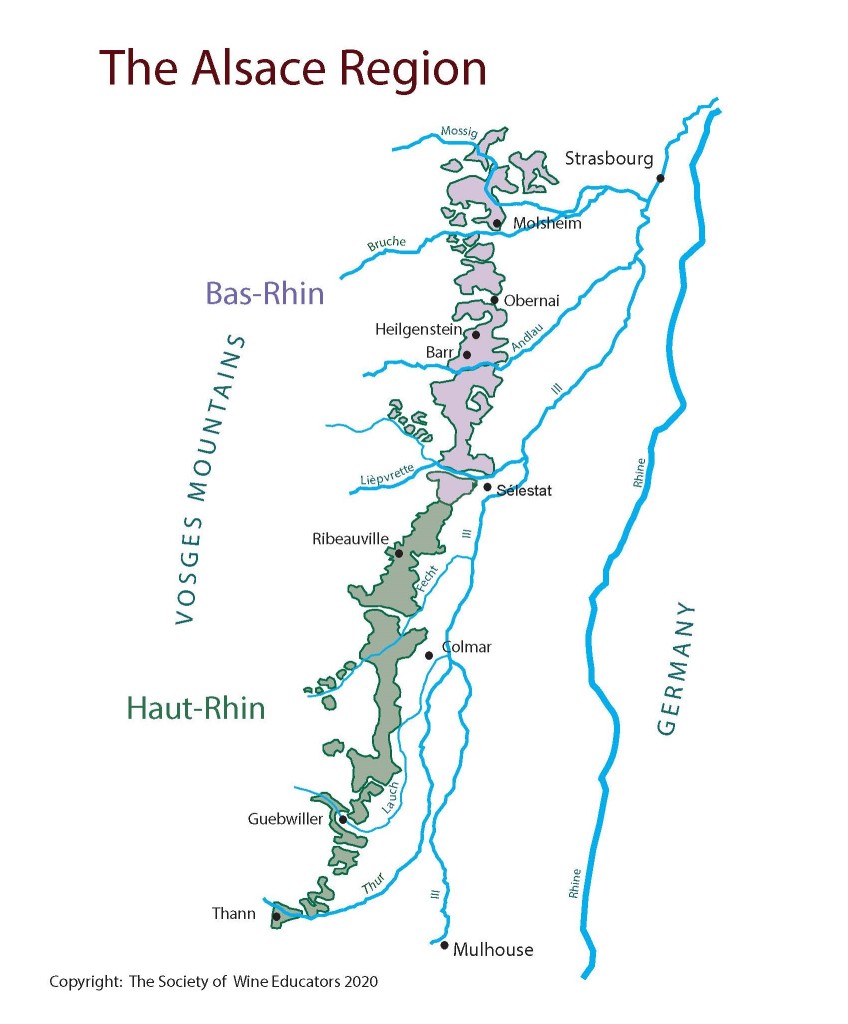
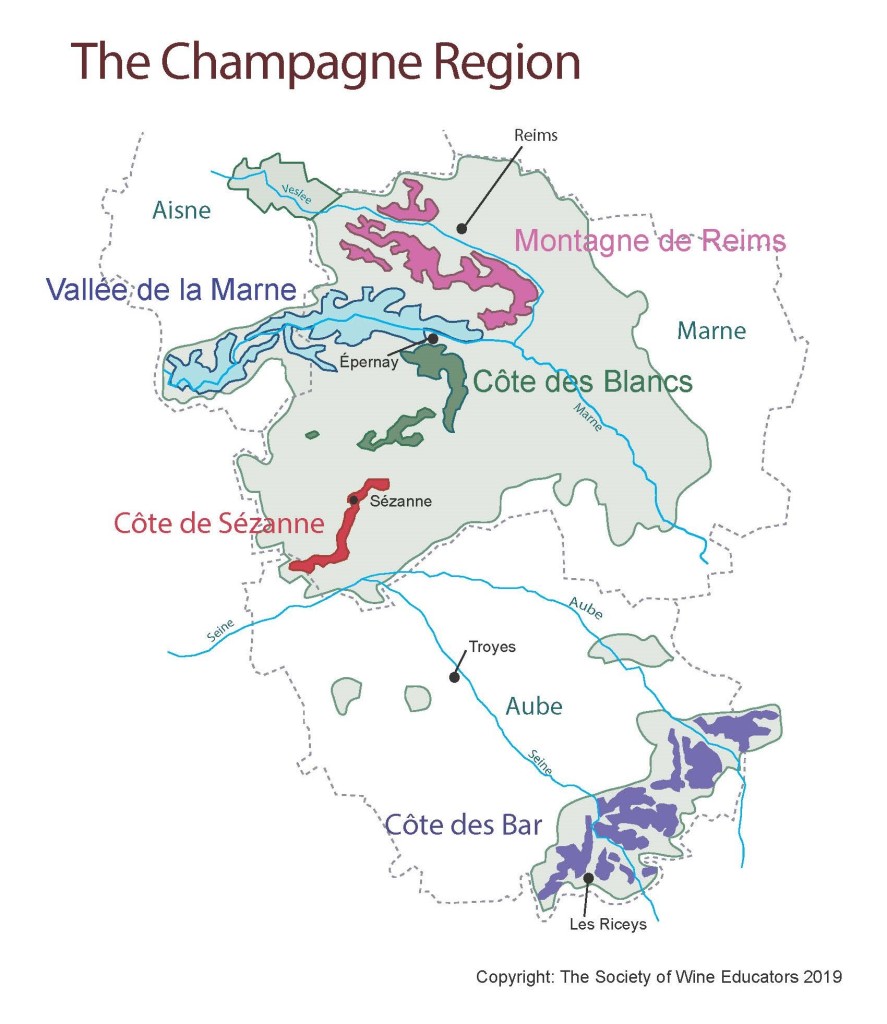
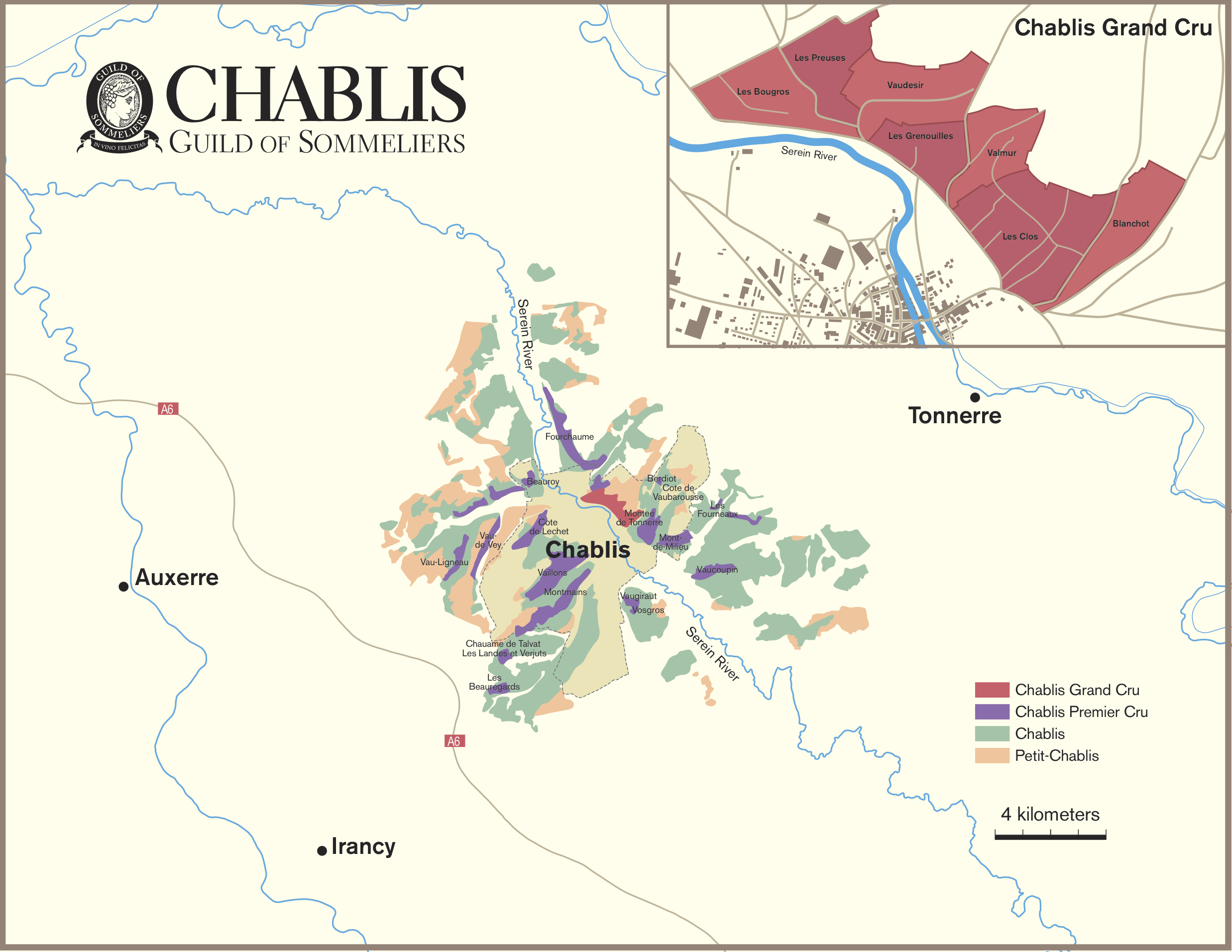
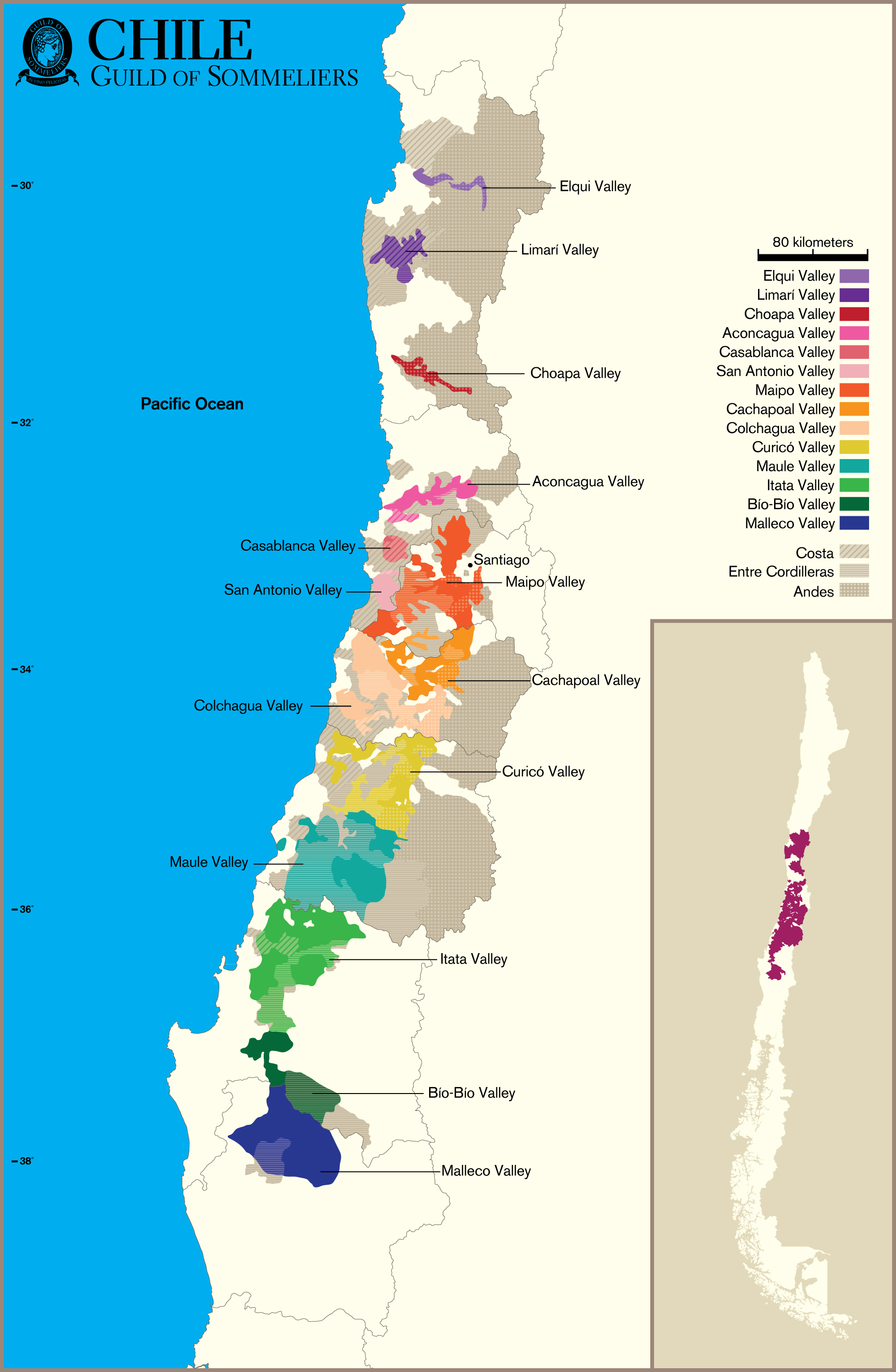
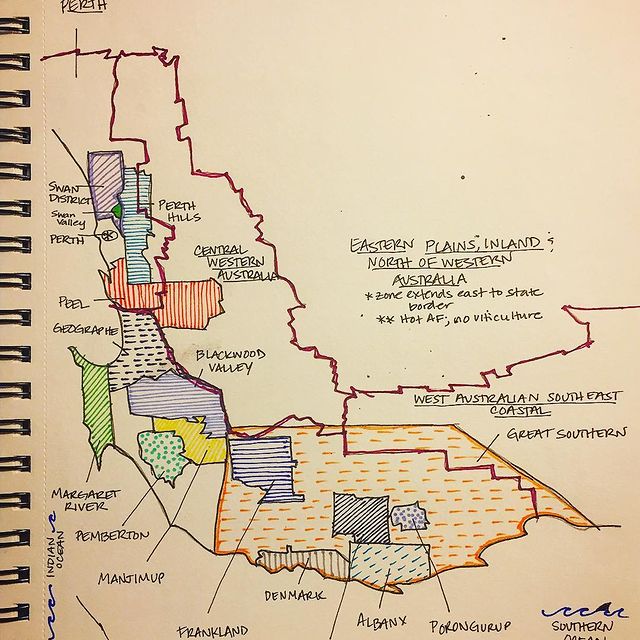
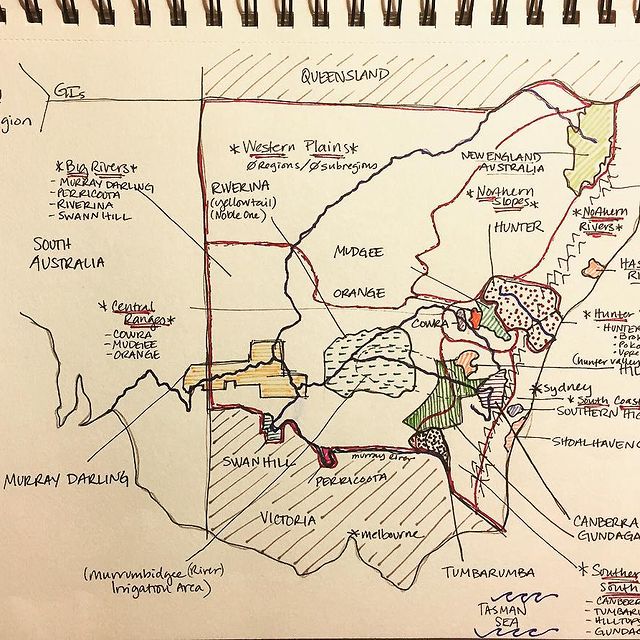
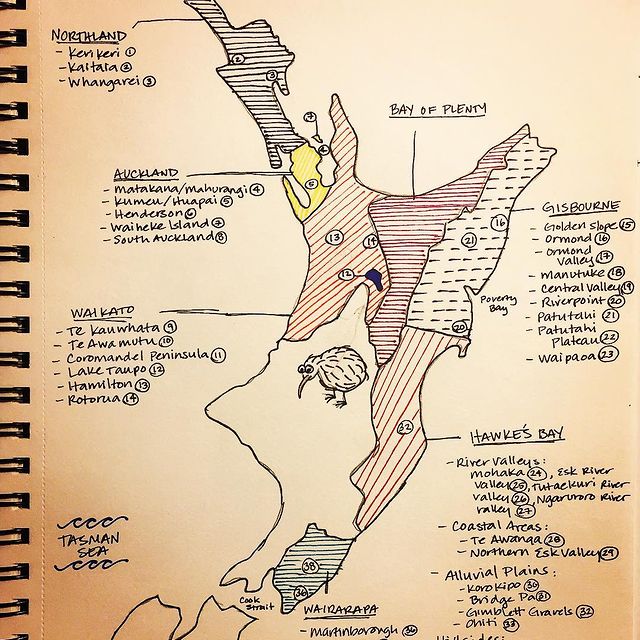
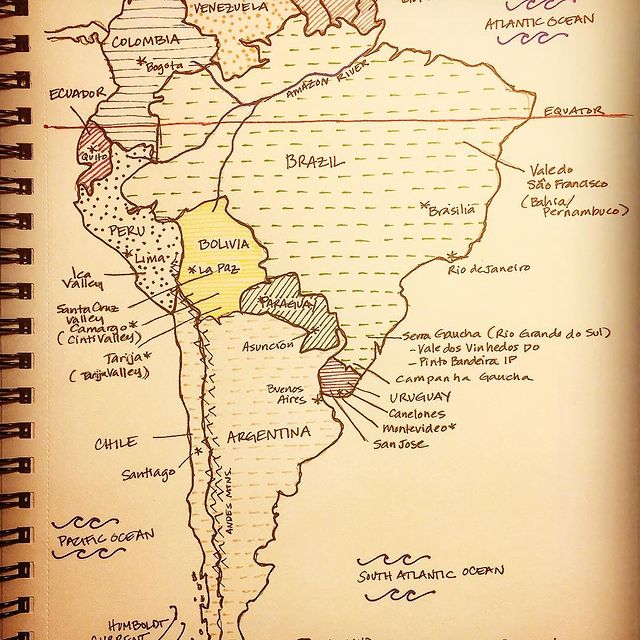
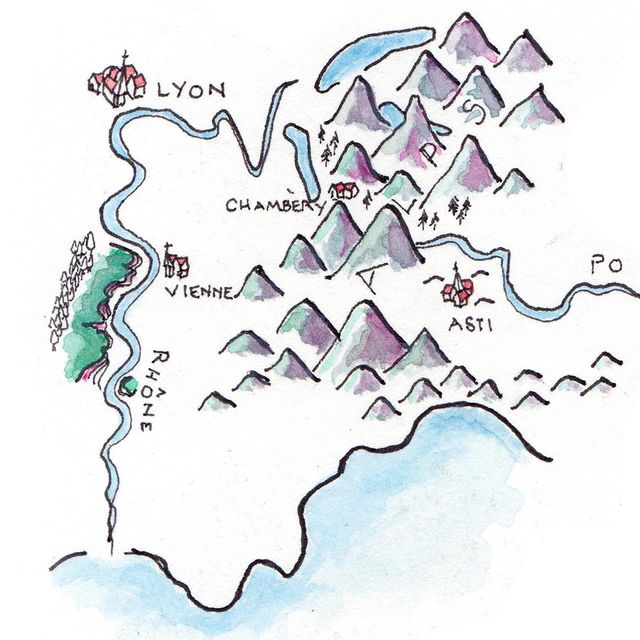
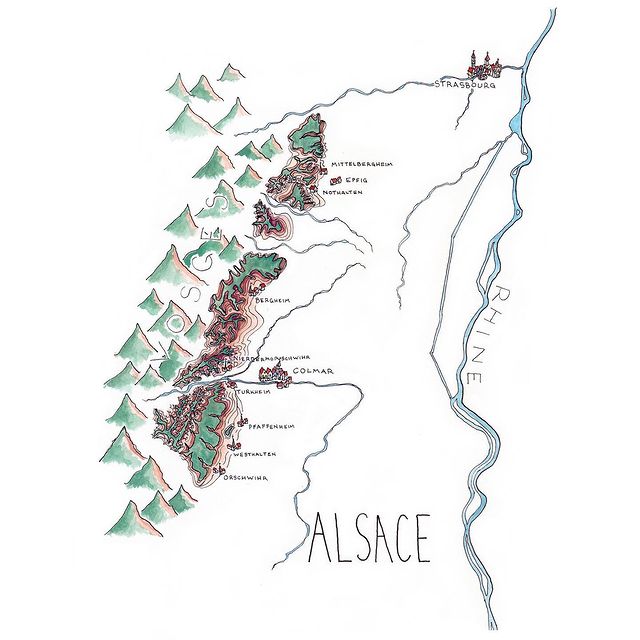
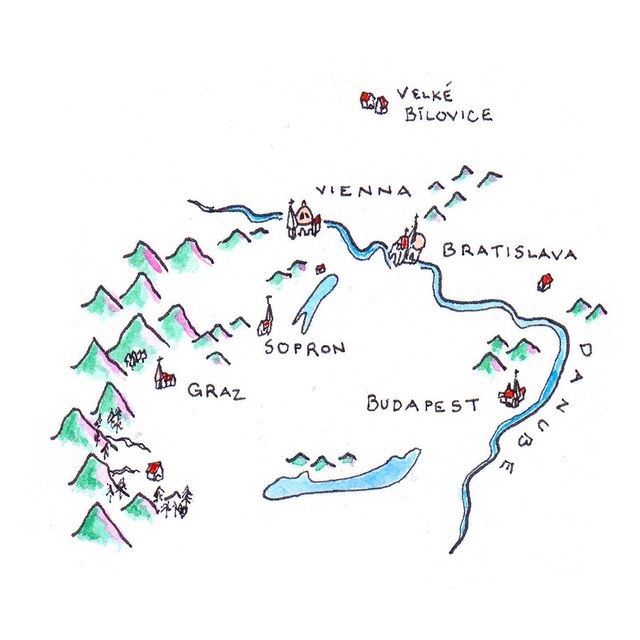
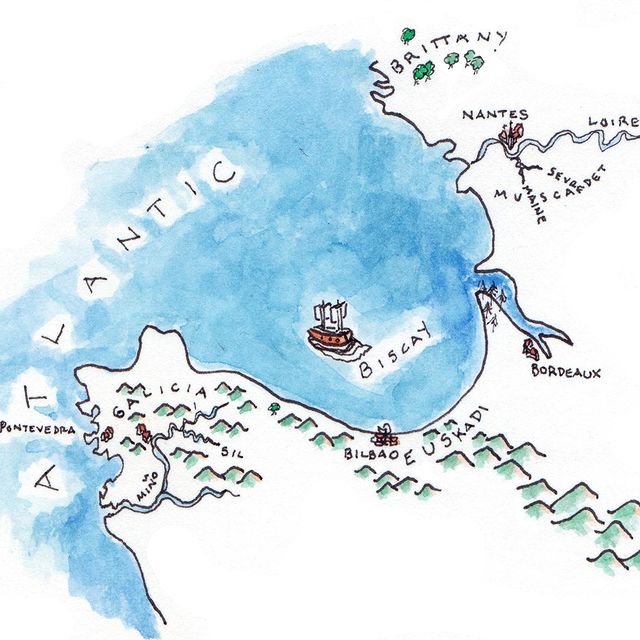
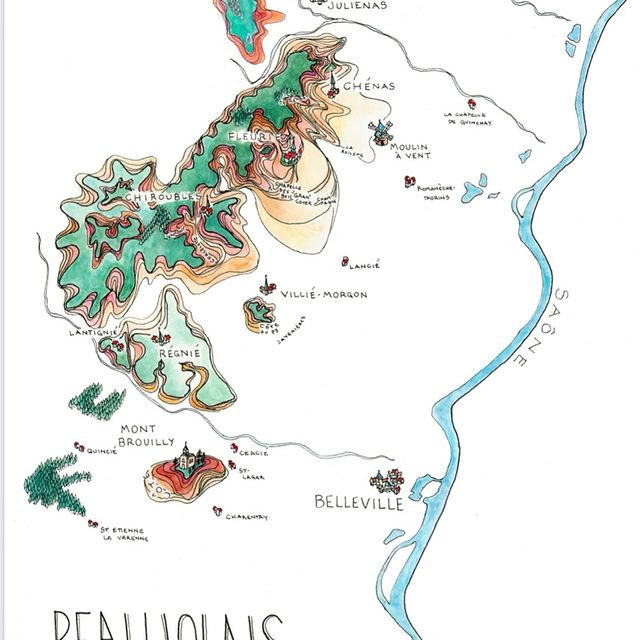
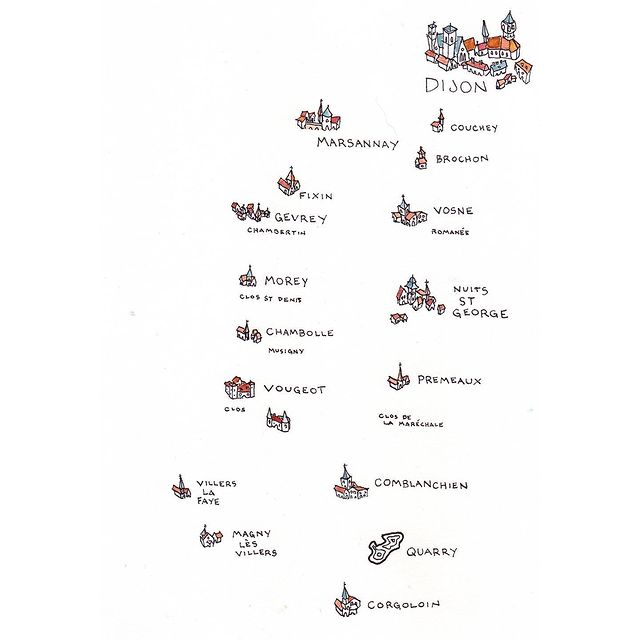
Like many wine lovers, I greatly apprecaite the exquisite pieces of wine maps with excrusiating details of geology, geography, soil, vine growing, winery information, etc., and collect as many as I can. Starting with the detailed professional maps from the World Atlas of Wine by Jancis Robinson and Hugh Johnson:
And many many, many, more, like Jasper Morris's most informative maps in Inside Burgundy, Peter Liem's reprinted maps of Champagne region in his Champagne book, Jane Anson's most updated Bordeaux maps that visualizes vintages, soils, climates, and more, ...
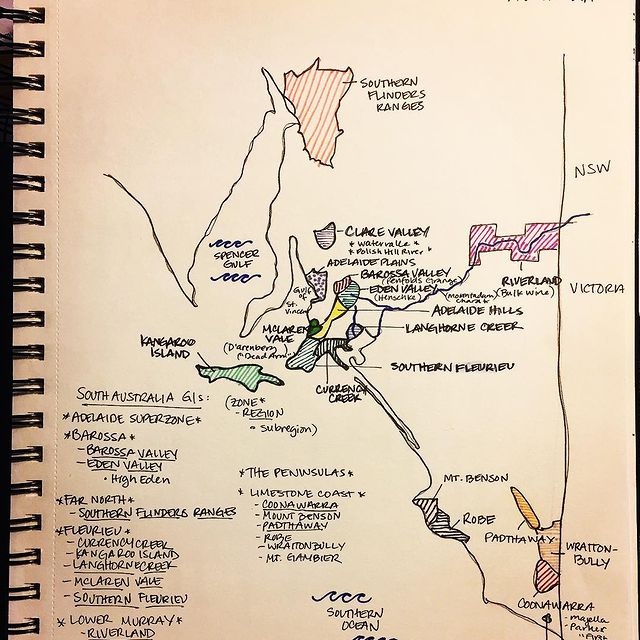
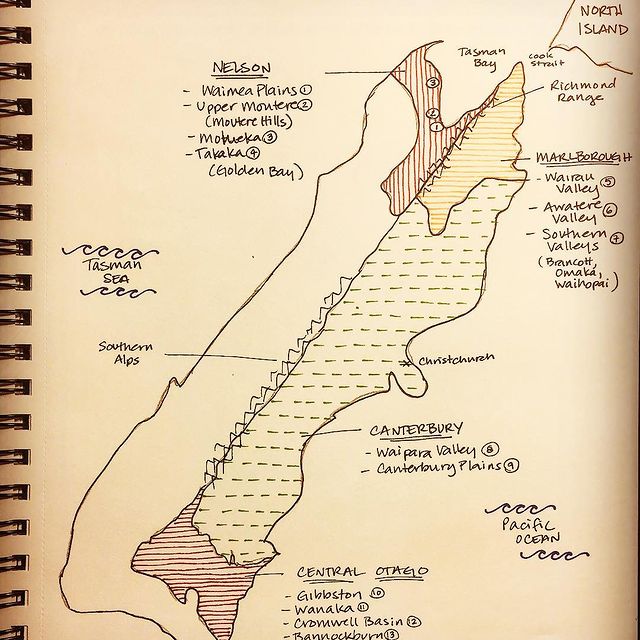
My obsession with exquisite wine maps --- especially those that perfectly combine dense, precise information and aesthetics knows no bounds. But Mapmaking has been a labor intensive and time-consuming process that requires extensive and in-depth knowledge of visual design, geography, perception, aesthetics, etc., on the part of cartographers or designers, despite the powerful modern softwares like arcGIS and Adobe Illustrator that have partially eased the process compared to manual mapdrawing. I've always lamented how few wine regions James Singh have covered so far with his masterful skills of watercolor mapping. What if, given a basic professional wine map of Burgundy, and a beautiful watercolor map (like Children's Atlas of Wine maps) of another region, say Bordeaux, we could automatically generate a beautifully rendered watercolor map of Burgundy in the style of the Bordeaux map!?
Luckily, computer vision researchers have been working hard on this exact problem --- well, almost! --- and with the era of deep learning, the subject of neural style transfer that exploded circa 2015 swept the field with breathtaking results, answeing questions like, what would Monet have painted if he saw Degas's ballet dancers, and what Degas would have painted if presented with Monet's garden?
Given the content image on the top left, and the three style images representative of the three artists --- JMW Turner's The shipwreck of the Minotaur, 1805-1810..., Vincent van Gogh's Starry Night, and Edvard Munch's The Scream, shown at the left bottom corners of the rest three images, as the respective style images, what L. Gatys and colleagues proposed as the neural style transfer algorithm generated the pleasing results of the accordingly stylized paintings. A brand new era began ever since...
How about applying to wine maps? Give me some watercolor artisanal wine maps, in bulk, please! Turns out existing cutting edge computer vision research does have its own share of foes... And in most cases, the algorithm does not do well, especially when it comes to tiny blocks of texts intertwined with complex artistic patterns... But here is a promising first step --- uCAST, unsupervised CArtographic Style Transfer, by me:
We will discuss the ins and outs of how to make it work, and what the field of neural style trasnfer, along with its close sibling image-to-image translation, is all about in the next part --- AI Talk.
AI Talk
AI Talk -- Technical
Image-to-image translation methods have gained significant traction over the past few years ever since the first unified framework based on conditional GANs was proposed by Phillip Isola and colleagues (2017), though the idea dates back at least to image analogies. Such methods require image pairs each of which include one image of the original style, and the other of the desired style, sharing the exact same content preferably perfectly aligned. To relax such a somewhat restrictive constraint for greater practical accessability, unsupervised image-to-image translation methods were proposed for unpaired image datasets by introducing additional constraints by either preserving certain properties such as pixel features, semantic features, and latent spaces, etc., or through loss functions to ensure cycle consistency (2017), distance consistency (2018), geometry consistency (2019), etc. Such methods work great as long as within each set, the image styles are consistent and different sets of images don't differ too much in terms of domain. For instance, transfering cats to dogs would probably work well whereas transfering cats to airplanes probably woouldn't. To solve this domain shift problem and enable models to generate diverse styles, multi-domain and multimodal methods (BicycleGAN (2017), MUNIT (2018), DRIT++ (2020), StarGAN) have also been introduced to generate diverse images across multiple different domains. The current work is also related to the instance-level image-to-image translation methods, which improve upon the global methods mentioned above in complex scenes. InstaGAN (2019) was the first work to tackle instance-level translation. It takes as input objects’ segmentation masks in the two domains of interest, and translates between the object instances without altering the background. In contrast, INIT (2019) and DUNIT (2020), both instance-level image translation methods, translate the entire image. INIT (2019) propose to define a style bank to translate the instances and the global image separately. During training, INIT (2019) treats the object instances and the global image independently, thus at test time, it does not exploit the object instances, going back to image-level translation. DUNIT (2020) propose to unify the translation of the image and its instances, leveraging the object instances at test time. uCAST (2021) seeks to translate the entire image as well, by leveraging contrastive learning, CUT (2020) proposes a simple patch-based image synthesis approach via maximizing the mutual information between corresponding patches in the input and output images. uCAST (2021) deviates in that none above considers paralleled text style transfer which is unique to the task of uCAST (2021).
Neural style transfer performs image-to-image translation by synthesizing a novel image by combining the content of one image with the style of another image by matching the Gram matrix statistics of pre-trained deep features. Local or semantic style transfer methods emphasize semantic accuracy. For instance, Li et al. (2016) match each input neural with the most similar patch in the style image for targeted transfer, Chen et al. (2016) preserves the spatial correspondence by way of masking and higher order style statistics to generalize style transfer to semantic-aware or saliency-aware neural algorithms. Gatys and colleagues (2016) transfer the complete ``style distribution`` of the style image through the Gram matrix of activated neurons. Fujun Luan (2017) further improves by incorporating a semantic labeling of the input and style images into the transfer procedure so that the transfer happens between semantically equivalent subregions. By introducing a contextual loss, ContextualLoss (2018) investigates semantic style transfer without segmentation for non-aligned images. Efforts such as Gu et al. (2018) and Huang et al. (2017) have been made to synthesize both local and global style transfer methods to enjoy the best of both worlds. None of this body of work distinguishes artistic patterns and artistic texts separately, and when applied to functional artworks, words tend to be illegible, misplaced, or not correspondingly stylized.
Neural font and artistic text synthesis studies apply neural style transfer methods to generate new fonts and text effects. Font style transfer problems have been explored in various aspects, ranging from Atarsaikhan et al. (2016) where Gatys et al. (2016) was directly applied, to Azadi et al. (2018) where a conditional GAN model for glyph shape prediction and an ornamentation network for colour and texture prediction are trained in an end-to-end manner to achieve multi-content few-shot font style transfer. Text effects transfer was introduced by Yang et al. (2017), in which a texture-synthesis-based non-parametric method was proposed. Yang et al. (2018) synthesize artistic style and target texts in an unsupervised manner that blends seamlessly into the background image. Texture Effects Transfer GAN (TET-GAN) jointly train two parallel subnetworks for text style transfer and removal to provide more seamless integration of text effects into background images. Yang et al. (2019) control the stylistic degree of the glyph with a bidirectional shape-matching framework.
As was articulated in MUNIT (2018), let us distinguish between example-guided style transfer, where the target style comes from a single example, and collection style transfer, where the target style is defined by a collection of images. The framework we propose as uCAST accommodates both.